Hauptinhaltsblöcke
Abschnittsübersicht
-
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
Welcome! This self-paced course was created as part of the CRAFT-OA project by Anastasiia Afanaseva and edited by Jorina Fenner and Xenia van Edig at TIB – Leibniz Information Centre for Science and Technology. This page represents the first version of this course, published in June 2025.
The course is split in two parts: The present course has a focus on the principles of digital preservation and how they work. The other course introduces practical first steps in digital preservation of journals while not going into detail on the technical functionalities of digital preservation.
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
Who is this course designed for?
The couse is primarly designed for Diamond OA journal publishers and editors. Therefore, it assumes a certain level of knowledge in the field of Open Access, but does not require familiarity with digital preservation.
What will you know or be able to do after completing the course?
- You will be able to tell the key characteristics of digital preservation/long-term archiving.
- You will be able to name factors why they are important.
- You will be able to list what options are available for long-term archiving.
- You will be able to discuss the preconditions for republication in case the journal is discontinued.
How to use this self-paced course?
Particants may choose the topic of their interest from the table of contents on the left or go through the course consecutively. In this way, you may also choose the level of detail that you wish to persue on a given topic. At the end of each section you will be able to test what you have learned in a short exercise.No login or account are required, you can work on the material at your own pace and return to it at any point in time. The section "Additional material" provides insights on how the topics for this course were selected.
-
-
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
What is long-term archiving/digital preservation?
Digital Preservation “refers to the series of managed activities necessary to ensure continued access to digital materials for as long as necessary … to all of the actions required to maintain access to digital materials beyond the limits of media failure or technological and organisational change” (Glossary - Digital Preservation Handbook, n. d.) The terms "digital preservation" and "long-term archiving" are frequently used interchangeably.
The key goals of digital preservation include maintaining the authenticity, integrity, and usability of digital objects despite technological changes and format obsolescence. This involves regular updates, format migrations, and adherence to standards and best practices.
Digital preservation has 3 main levels:
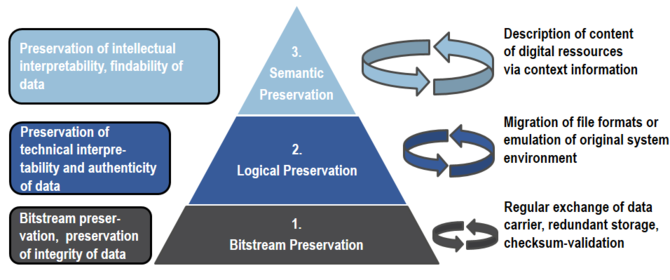
Image: Publisso, Preservation Planning and Action (https://www.publisso.de/en/digital-preservation/preservation-planning)
This image exemplifies that redundant storage is not enough for digital preservation - it is merely a basis for it.
The following video describes the basics of bitstream preservation some of which can be done by creators and organisations themselves. It provides an introduction to the basic principles, however, in many cases not all of the mentioned aspects are subject to the editors' decision-making.
Video: Digital Preservation Coalition, Just Keep the Bits: an introduction to bit level preservationFurthermore, it is important to take note of the following aspects:Digital preservation and digitization are not the same thing: Digitizing content only creates a copy of the analog content which is supposed to be preserved. It may be lost for scholarly record before the printed version of the journal.
Backups are important but digital preservation and backup are not the same thing: A backup is a copy of data made for the purpose of recovery if the original data is lost or damaged. Backups are typically short-term solutions designed for immediate data recovery. They do not necessarily take into account the long-term accessibility or usability of data as technology evolves. Backups are often periodic and automated, but are not a comprehensive strategy for preserving digital content over time. Format migration and preservation policies are not in place. The data in a backup is not structured. Metadata is very sparse, making objects difficult to find and manage.
Hence, digital preservation is a complex process where all the actions that ensure that content is transferred between a provider and a consumer need to be well thought out and documented. The creation of extensive metadata is necessary to ensure that files retain their readability and intelligibility, and that access to them is aligned with the relevant rights. This is exemplified in the OAIS model, where content is "travelled" within different information packages (IP) containing metadata and the document itself, with potential variations in format between packages.
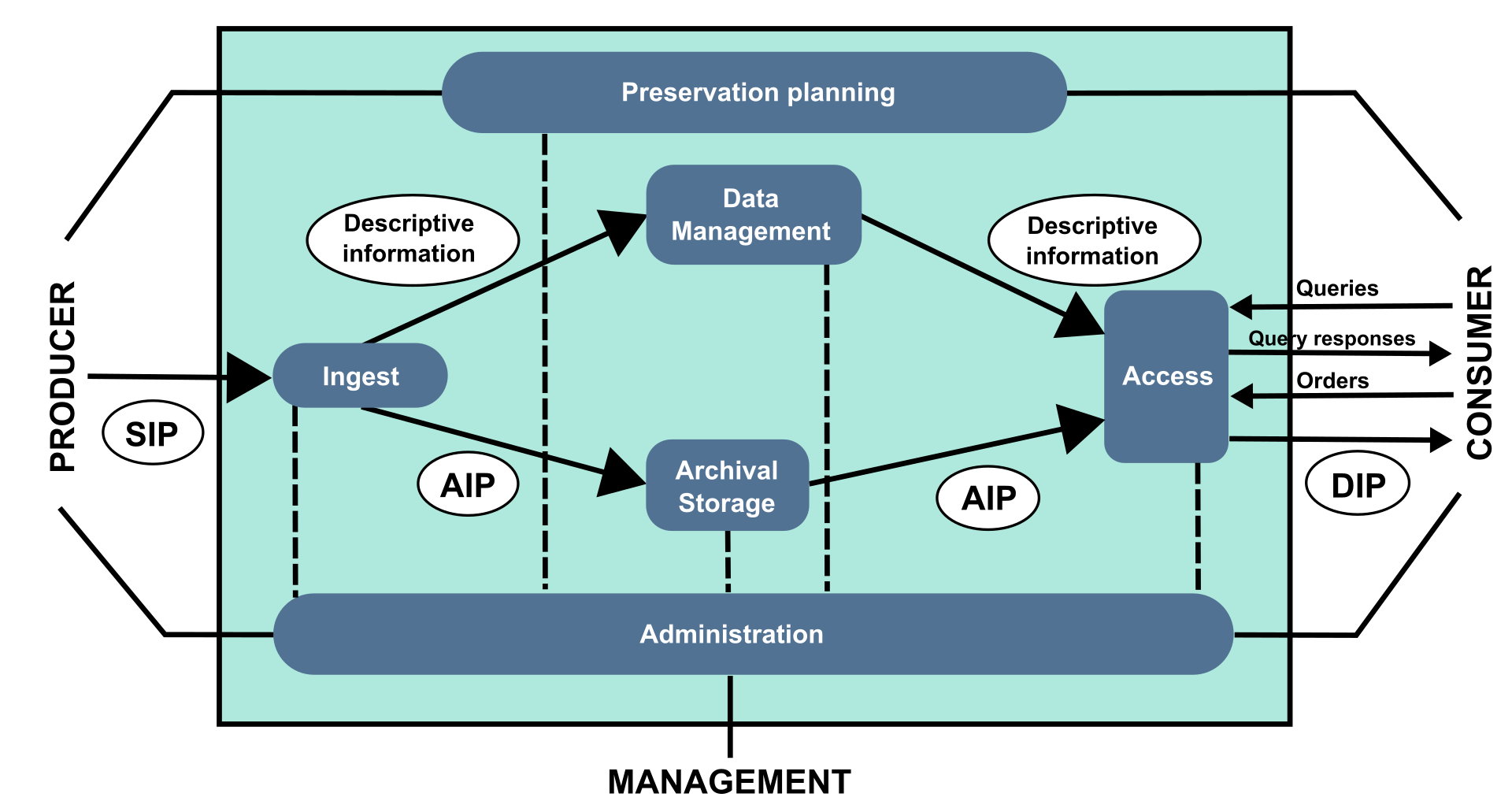
Image: Mathieualexhache (original work); Mess (SVG conversion & English translation), CC BY-SA 4.0 <https://creativecommons.org/licenses/by-sa/4.0>, via Wikimedia Commons
If you would like dive deeper into this issue visit the Digital Preservation Handbook from the Digital Preservation Coalition.
-
Teilnehmer/innen müssenAls erledigt kennzeichnenPick a term from the section above and add a definition to our glossary OR make a change or one of the existing terms.
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
Digital preservation is critical for scholarly journals because:
- It ensures the integrity and traceability of the scholarly record: Preserving digital content ensures that the scholarly record remains accurate and reliable over time. It protects against data loss, corruption or unauthorised alteration, thereby maintaining trust in scholarly work. This is essential for verifying research results and supporting reproducibility, ensuring that all research data and publications can be traced back to their original sources.
- It allows for access after the discontinuation of a journal: If a journal ceases publication, the preserved digital content remains accessible to researchers and the public under certain conditions (cf. ch. 2 "Digital preservation services and how they work"). This helps to ensure the longevity and continued availability of valuable scholarly work. Implementing digital preservation practices can significantly enhance the credibility and sustainability of a journal.
- It ensures compliance with standards and requirements, such as:
- Crossref lists under Member's Obligations "Archives. The Member shall use best efforts to contract with a third-party archive or other content host (an "Archive") (a list of which can be found here) for such Archive to preserve the Member's Content and, in the event that the Member ceases to host the Member's Content, to make such Content available for persistent linking" (Membership Terms, 2022)
- Plan S, which lists under "Mandatory technical conditions for all publication venues" "Deposition of content with a long-term digital preservation or archiving programme (such as CLOCKSS, Portico, or equivalent)"
- DOAJ application criteria best practice: “The journal content should be continuously deposited in a long-term digital archiving system."
- The Diamond OA Standard: "The publisher has a publicly displayed archival and digital preservation policy which is consistently implemented. The published content is deposited in at least one digital preservation service. (REQUIRED)“ (DIAMAS Project Consortium, 2024, pp. 28-29)
It should be noted that most standards only address preservation services listed in the Keepers Registry and not other institutional and national services.
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
What is the current situation regarding digital preservation of OA journals?
Current research unterlines the urgency for Diamond OA journals to increase awareness and activities around long-term archiving:
"Open is not forever: A study of vanished open access journals" (Laakso et al., 2021) showed 2020 that 174 OA journals vanished between 2000 and 2019. These journals spanned various research disciplines and geographic regions, but there were more vanished journals among SSH, scholar-led and North American journals.
As of 2024, about 28% of scholarly journals registered with Crossref were not preserved by any of the big preservation agencies (Eve, 2024). More details may be found here: Digital Scholarly Journals Are Poorly Preserved: A Study of 7 Million Articles.
Additionally, The OA Diamond Journals Study found 2021 that „permanent preservation is the requirement seeing the lowest compliance amongst journals at 28.9%, only 19.1% for OA diamond journals.“ (Bosman et al., 2021, p. 73) and „this rate of no-preservation rises to 71.9% of the respondents with less than $/€1,000 of annual budget" (Bosman et al., 2021, p. 96). -
-
-
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
Digital preservation services are critical to ensuring the longevity and accessibility of scholarly content, particularly for OA journals. These services protect against data loss due to technological change, institutional change and other potential disruptions. Using a variety of technological frameworks and collaborative efforts, digital preservation services maintain the integrity and availability of scholarly works.
This section examines some of the international digital preservation services - LOCKSS, CLOCKSS, PKP PN, Internet Archive, Portico and PubMed Central - detailing their unique approaches and contributions to the protection of digital content. LOCKSS, CLOCKSS, PKP PN and Portico are so called "dark archives" that only give access to the data when the publisher cannot do it anymore. Internet Archive and PubMed Central are "bright archives" that publish the content at their websites as soon as they have it.
It is important to note that, according to the official websites of these services, Portico is the only preservation service that migrates formats and ensures logical preservation. However, Portico provides only limited details of its workflows. All the other services mainly guarantee bitstream preservation without necessarily protecting content from format obsolescence. It may therefore be advisable to combine the options of a certified institutional/national library, which undertakes all preservation actions, and a well-known international service that stores content repeatedly, republishes it, is registered with Keepers and meets the requirements of Plan S, NIH or DOAJ's recommendations for best practices.
LOCKSS (Lots of Copies Keep Stuff Safe) is a program developed by the Stanford University Libraries at 1999. It is “a principle, a program, a community, and a software application” with solutions for distributed technical infrastructure (FAQ - CLOCKSS, 2024). It is based on a peer-to-peer network of multiple copies and servers that ensures the permanent availability of digital content through numerous distributed copies.
Several networks have been created on this basis, such as the Global LOCKSS Network (GLN LOCKSS). This system enables the funding libraries to access content locally when it is no longer available from publishers. Although publishers participate in the GLN at no cost, GLN preserves a small number of OA Journals. Sprout & Jordan (2018, p. 247) underline that it held “around 200 OJS titles […] of approximately 10,000” in 2018. This is due to the fact that the funding libraries choose the content to preserve, so they often used to opt for post-cancellation service for the paid journals (Sprout & Jordan, 2018, p. 248). It is nevertheless possible for any scholarly journal to apply for preservation free of charge (cf. https://www.lockss.org/gln#publishers).
On the basis of LOCKSS, many other services and preservation communities were launched, among them national initiatives. The lists of them can be found at the LOCKSS website: https://www.lockss.org/join-lockss/networks and https://www.lockss.org/join-lockss/case-studies#preserving_national_open-access_scholarly_output.
The main global long-term preservation services based on LOCKSS for open access journals are CLOCKSS and PKP Preservation Network (PKP PN).
CLOCKSS (Controlled LOCKSS) is a not-for-profit organization, funded by a network of publishers and libraries and governed by a Board with representatives of those institutions. Utilizing the LOCKSS technology, CLOCKSS preserves content in its original formats and ensures long-term data validity through a polling-and-repair mechanism, with mirror repositories at twelve major academic institutions worldwide guaranteeing long-term preservation and access. CLOCKSS collaborates with publishers to secure perpetual preservation rights and access to their content, which is ingested and verified for integrity at specialized servers. The content is then managed and preserved through continuous audit and repair processes. Upon a trigger event, content is migrated to the latest formats, copyright checks are performed, and it is made publicly available under Creative Commons licenses, ensuring that scholarly contributions remain accessible and open to all. They are “directly available via Open URLs through Crossref, or either of local library link-resolvers or from CLOCKSS triggered contact” (How CLOCKSS Works - CLOCKSS, 2024).
Moire information in the CLOCKSS service may be found here:
CLOCKSS website: https://clockss.org/
Schonfeld, R. (2024). Kitchen Essentials: An Interview with Alicia Wise of CLOCKSS [Blogpost] https://scholarlykitchen.sspnet.org/2024/02/20/kitchen-essentials-alicia-wise-clockss/
Video: Thib Guicherd-Callin on the technology behind CLOCKSS:
The PKP Preservation Network (PKP PN) is a digital preservation initiative designed specifically for journals that use the Open Journal Systems (OJS) software which is common among OA journals that are published by small publishers and are at risk of loss. Launched in June 2016 by the Public Knowledge Project (PKP), it addresses the critical need to safeguard content from OJS journals, many of which lack preservation through established services like CLOCKSS or Portico. Its usage is free of charge for OJS users: “PKP has found ways to automate the work of getting the journals into the PN, meaning that the service is not time-intensive to maintain once launched, and that staffing costs are kept to a minimum. One of PKP’s goals in developing the PN was to maintain a low barrier to entry to enable as much participation as possible. The resulting network provides free preservation services for any OJS journal that meets a few minimum requirements” (Sprout & Jordan, 2018). These minimum requirements include installing the plugin, running on OJS 3.1.2 or newer, having an ISSN and having published at least one article (for more information cf. https://docs.pkp.sfu.ca/pkp-pn/en/).
If you would like to learn more about the PKP Preservation Network, consider looking in to these resources:
PKP Documantation: https://docs.pkp.sfu.ca/pkp-pn/en/
Sprout, B., & Jordan, M. (2018). Distributed Digital Preservation : Preserving Open Journal Systems Content in the PKP PN [Article] https://dx.doi.org/10.14288/1.0378578Video: Public Knowledge Project (2022). Registering for the PKP Preservation Network:
One more important preservation service, not based on LOCKSS, is Portico. It was founded in 2005 and is supported by over 1288 libraries and 1105 publishers (Facts and Figures - Portico, 2024). Portico's services have evolved over time to respond not only to subscription content but also to open access materials and to emphasise the inclusion of smaller publishers (Wise, 2021, p. 3). Portico and CLOCKSS have also developed very complex workflows enabling the preservation of “features such as embedded visualizations, multimedia, data, complex interactive features, maps, annotations, and in some cases they may depend on third-party platforms or APIs, such as YouTube or Google Maps” (Millman, 2020).
Consider these resources, if you would like to learn more about Portico:
Portico Website, Why Portico: https://www.portico.org/why-portico/
Wittenberg, K., Glasser, S., Kirchhoff, A., Morrissey, S., & Orphan, S. (2018). Challenges and opportunities in the evolving digital preservation landscape: Reflections from Portico. Insights the UKSG Journal, 31, 28. https://doi.org/10.1629/uksg.421Ingenta (2019). Ingenta Webinar – Archiving your Valued Content with Portico.
The Internet Archive, which has been active in the archiving and provision of digital content since 1996, has been involved in a number of projects in relation with OA journals. For example, thanks to the Mellow Foundation, Columbia University Libraries has archived several "small, relatively obscure titles" that do not use OJS and do not appear in DOAJ using the Internet Archive's Archive It tool (Regan, 2016, p. 94), which is still available. Since 2017, the Mellow Foundation has also supported another project in which the Internet Archive (1) developed the Fatcat-Wiki to record the status of long-term archiving while providing open access to the articles; (2) processed all the scholarly publications already captured and made them available through Internet Archive Scholar (for more detialed information cf ‘How the Internet Archive Is Ensuring Permanent Access to Open Access Journal Articles | Internet Archive Blogs’, 2020). Currently, the “Internet Archive makes basic automated attempts to capture and preserve all open access research publications on the public web, at no cost. This effort comes with no guarantees around completeness, timeliness, or support communications” (For Publishers - The Fatcat Guide, n.d.). It operates on basis of metadata harvesting from metadata catalogs, like Crossref and DOAJ, and requires PIDs. There are also possibilities to save content in the Internet Archive that has not been harvested automatically, e.g. by a paid subscription service Archive It (for more detailed information cf. https://support.archive-it.org/hc/en-us/articles/208111766-Want-to-know-more-about-Archive-It)
If you would like to learn more about the Internet Archive, these may be useful resources:
The Fatcat Guide, For Publishers: https://guide.fatcat.wiki/publishers.html
The Fatcat Guide: https://fatcat.wiki/
Internet Archive Blogs, How the Internet Archive is Ensuring Permanent Access to Open Access Journal Articles: https://blog.archive.org/2020/09/15/how-the-internet-archive-is-ensuring-permanent-access-to-open-access-journal-articles/
CNI Fall 2023 Project Briefings, Multi-Custodial Approaches to Digital Preservation of Scholarship: https://www.cni.org/topics/digital-preservation/multi-custodial-approaches-to-digital-preservation-of-scholarshipPubMed Central (PMC) provides a digital preservation service for biomedical and life sciences literature. Articles are ingested through direct submissions from publishers and authors, ensuring compliance with metadata and format standards like (JATS) XML for consistency. Rigorous quality control checks verify the integrity and completeness of submissions. Content is stored redundantly across multiple locations to prevent data loss and is subject to regular format migration to adapt to evolving technologies, while permanent URLs ensure stable access. PMC supports compliance with funding agencies' public access policies in the US and is a well-known database.
To learn more about PubMed Central, consider this ressource:
PMC, For Publishers: https://www.ncbi.nlm.nih.gov/pmc/pub/pubinfo/
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
- The table you can download above compares the described preservation services according to the following criteria
- Governance
- Costs (in USD, per year)
- Open Source
- Preservation method
- What can be preserved?
- Journal content (as of June 2024)
- Access to preserved content
- How to apply
- Publisher platforms with integration to the service
- Trigger event definition
The information presented is based on Laakso et. al (2021) and additional information on the Internet Archive and PubMed Central collected by Anastasiia Afanaseva in July 2024. -
Teilnehmer/innen müssenAls erledigt kennzeichnen
Which publication software supports which preservation services?
D3.2 of CRAFT-OA collected information from experts on OJS, Janeway and Lodel on the respective software's support for digital preservation services/long-term archiving. The answers are captured in the following table from the report: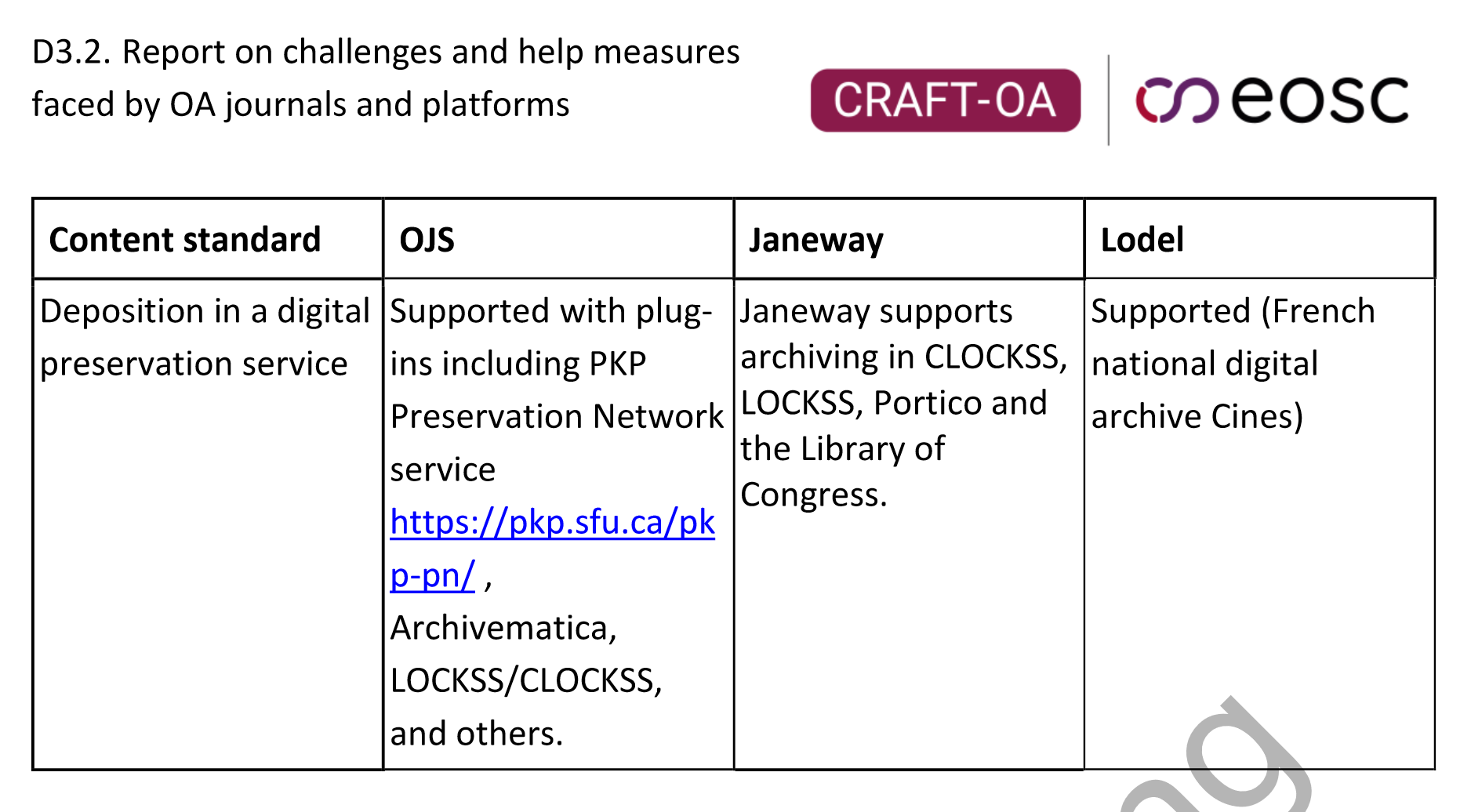
Table: CRAFT-OA Deliverable 3.2: Report on challenges and help measures faced by OA journals and platforms (Laakso et al., 2024, S. 73)
It should be added to the table above that there is a Portico plugin available for OJS (https://github.com/jonasraoni/portico) as well. Additional information on the support of publishing software for long-term archiving can also be found in Finding the Right Platform: A Crosswalk of Academy-Owned and Open-Source Digital Publishing Platforms. For German speakers, there is also a description of the currently most widely used plugins for long-term archiving systems in OJS and general steps for their installation and use: Langzeitarchivierung in Open Journal Systems (OJS)
-
Teilnehmer/innen müssenAls erledigt kennzeichnenWould you like to test your knowledge after working through this chapter? Take this private self-assessment quiz.
-
-
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
"Trigger events": How to ensure the content will be accessible even if a journal discontinues?
One of the goals of long-term archiving is to ensure that content remains accessible even when its publisher can no longer provide it (e.g., a journal was discontinued or the hosting of its website is no longer paid). If the content is stored in a "dark archive", it can be re-published after a "trigger event" occurs.The following aspects should be checked for a journal's content to remain findable and accessible if the journal ceases publication or encounters other major changes and challenges:
- Under which licence was the content publised?
This is important to determine whether the preservation service has the right to republish the content. This should be declared in a contract or by the use of a relevant Creative Commons licence. The same is applicable for repositories: Are they allowed to give this content to a preservation service if they use one? And may the content be republished? - Does the preservation service publish/display the archived content?
This could, e.g. include a presentation infrastructure. Here, it may be of interest what the access modalities are.
For example, the German National Library archives web content and OA journals, but these can only be consulted offline in the library and are not fully listed in its catalogue. So for OA journals archived there it can be advisable to find an additional service to increase accessibility and findability of content in case of discontinuation. - How is a "trigger event" defined?
It is recommended to create a workflow for informing the preservation service about potential challenges and for the period until the republication of the content. (Check downloadable Table in Part 2 for the biggest preservation services). - In the event that a journal or a publisher has ceased publication, who remains in contact with a digital preservation service?
In order for the preservation service to publish the content, it is essential that the journal manager (or the responsible person according to the workflow) contacts it after the discontinuation of the journal. For PKP PN, the process was described in (Sprout & Jordan, 2018, p. 249) as follows: “the trigger event can be notification by the journal manager or cessation of deposits into the PN after a period of inactivity. If a potential trigger event is detected, PKP staff will contact the journal to confirm its publication status, and if it is confirmed, approve the importing of preserved content into a special OJS instance – an “access node” operated by the PN where it will be openly accessible”. For CLOCKSS, “content must be unavailable for 6 months before it is triggered. It is important to observe that this delay is mandatory only when content is being triggered without the consent of the publisher. In all cases so far content has been triggered at the request of the publisher, and the technical process described below has taken 2-4 weeks.” (CLOCKSS: Extracting Triggered Content - CLOCKSS Trusted Digital Repository Documents, n.d.). The final sentence also emphasises the significance of communication with the publisher. Furthermore, the discontinuation of a title and its unavailability on the web are not straightforward to determine, necessitating additional work. This is not easily accomplished automatically (Laakso et al., 2021 ; Lightfoot, 2016), so that the publisher should not rely on a preservation service to determine it without being contacted. Hence, even seemingly mondane steps should not be overlooked, like to keep in mind if there is a possibility that the discontinuation of a journal could result in a journal manager changing their job position and/or contact email. In this case, it is vital to leave an alternative contact address that would remain operational even in such an event, so that the preservation service could continue communicating with a journal’s representative and publish their content.
- Under which licence was the content publised?
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
Let others archive and use your OA content!
Before going into greater detail on issues to keep in mind for digital archiving in the following section, this section explains easy steps in which a journal may increase the coverage, archivability and findability of its content:- Use persistent identifiers - not only are they critical for discoverability, but they are also used for metadata crawling by many of the major databases that could promote your content and store copies of it. For example, content with Crossref DOIs is harvested by OpenAlex and Dimensions, and can also be crawled and stored by the Internet Archive. OpenAlex preserves metadata years after journals cease publication. It is also gaining popularity in the bibliometric community, which can be beneficial for your journal's ranking.
- Publish a self-archiving policy on the journal's website and in Sherpa Romeo
- Encourage your authors to deposit copies of their work in repositories
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
How can publishers make the content more archivable?
This section addresses aspects which influence sucessful long-term archiving which also depends on the data quality of the content that is being archived. Unfortunately, some files are damaged upon arrival at a digital preservation service. Format conversion and file transfer are common points of failure as well. These issues are best addressed at the ealiest of the process. It is, therefore, advisable that editors take action to ensure their data is archivable and to avoid content loss. In the absence of a preservation service, this is of particular importance, as the files are stored in an unmonitored environment and the content producers may be unaware of the issues.Basic preconditions for archiving digital content
The first steps to ensure sucessful long-term archiving include:
- Ensure that documents are not password protected
- Provide metadata on the journal and the article level
- Use known file formats where possible
- Use established tools for format conversion and content creation so that your files are of good technical quality and can be saved, opened and migrated to another format
File format validation
Format validation is an automated process that ensures that a file is of a certain standard and technical quality. It answers, for instance, the following questions:
- Is this file really of a format it seems to be?
- Can the file be opened and read?
- Can the file be correctly converrted into another format? (E.g. if you are only planning to start offering a new format like XML, you may want to convert your files later. So it can be relevant even if you do not use any preservation service.)
- Are all the fonts embedded so that they will work in another computer environment?
As the formats are different, different tools may be used for file validation. For PDF files, for example, these tools may be made use of :
- pdfcpu
- open tools from the German National Library of Science and Technology (TIB): Pre-Ingest Analyzer ; Format Validator
- PdfInfo, ExifTool etc
Checksum
Files may also be damaged during upload or transfer. When you transfer large packages of files, there is a chance that not all the files will be transferred due to a technical error. One way to check this is with a checksum - a sequence of numbers and letters generated to confirm that a file has not been altered in any way. It is worth creating checksums to check the technical integrity of files, especially if you have workflows that involve many files. Some softwares already include this feature for uploading files. There are specialised programs for this, but a command line script may also be employed. One of the ways to regularly make checksums is using Total Commander. If you are using checksums, it is recommendable to display them in the frontend. In that way, users may check them themselves when downloading files from your site.
Supplements and enhanced formats
It is important to check whether the data is complete and whether all metadata, supplements, images, etc. are included in the publication package.
If you are using enhanced data, be aware that this presents a major challenge for interoperability, readability and archivability, and is best addressed at the production stage. For instance, it is advisable to not depend on external content to remain permanently accessible. Instead, it is necessary to ascertain that the publication has all the material needed, even if the original source of the content (for example, a video on YouTube embedded via iframe) is no longer available. If this applies for you, consider the Guidelines for Preserving New Forms of Scholarship (Greenberg et al., 2021) for more information.
If you would like to learn more about checking the quality of content to be archived, take these ressources into account:
Guidelines for Preserving New Forms of Scholarship (Greenberg et al., 2021)
Digital Preservation Handbook: Creating digital materials
An overview of potential challenges is provided in a video Preservation of New Forms of Scholarship about the enhanced content and the methods employed by preservation services to ensure the long-term viability of such content (Millman, 2020)
Recommendations from Internet Archive on optimising content for web crawling
-
-
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
After finishing the five chapters of this course, this cheat sheet summarises the most important points and key words for you:
- Understanding Digital Preservation
- Definition: Digital preservation involves a series of managed activities to ensure continued access to digital materials over time, despite technological changes or media failures.
- Goals: Maintaining authenticity, integrity, and usability of digital objects. This involves bitstream preservation (data integrity), logical preservation (format migration or emulation), and semantic preservation (context)
- Importance of Digital Preservation for Scholarly Journals
- Research Integrity: Ensures that research remains accurate, reliable, and traceable over time.
- Continued Access: Preserved content remains accessible even if the journal ceases publication.
- Compliance: Meets standards and requirements set by Crossref, Plan S, and the Diamond OA Standard.
- Digital Preservation Services
- LOCKSS (Lots of Copies Keep Stuff Safe): Distributed network ensuring permanent availability through multiple copies.
- PKP PN (Public Knowledge Project Preservation Network): Free service for OJS users to safeguard journal content based on LOCKSS.
- CLOCKSS (Controlled LOCKSS) and Portico are led by libraries and publishers. They are dark archives ensuring long-term preservation and republishing the content in case the publisher cannot do it anymore
- Internet Archive: Captures and preserves digital content, including scholarly publications, for public access, maintains Fatcat Wiki visualizing preservation status for multiple journals
- PubMed Central (PMC): Preserves biomedical and life sciences literature with compliance to metadata and format standards.
- Free Preservation Options for Diamond OA Journals
- PKP PN: For OJS users, offering automated preservation with minimal maintenance.
- DOAJ JASPER Project: Allows journals listed in DOAJ to apply for preservation via CLOCKSS and Internet Archive.
- There are also other LOCKSS Networks, national and institutional options for preserving scholarly content.
- Ensuring Content Archivability and Accessibility After Discontinuation
- Persistent Identifiers: Use persistent identifiers to ensure that your journal's articles and metadata may be collected and archived by others
- Open licenses: Use open licenses (and a self-archiving policy) to encourage authors to archive their articles in repositories.
- Technical Quality Checks: Ensures files are of good technical quality and meet preservation standards.
- Format Validation: Automated process to verify file standards and quality.
- Checksums: Ensures data integrity during transfers.
- Enhanced Formats: Managing enhanced data to maintain interoperability and archivability.
- Trigger Events: Defined workflows to republish content when a journal ceases publication
- Communication: Importance of maintaining contact with preservation services for smooth content access.
-
Teilnehmer/innen müssenAls erledigt kennzeichnenWould you like test your knowledge after completing this course? Take this quick and private test.
-
-
-
Teilnehmer/innen müssenAls erledigt kennzeichnenThis section describes how the course seeks to address the challenges identified by the available research on the needs of the Open Access publishing community.
-
Teilnehmer/innen müssenAls erledigt kennzeichnen
These resources provide additional reading for anyone interested in learning about certain aspects of long-term archiving in more detail:
Armengou, C., Aschehoug, A., Ball, J., Bargheer, M., Bosman, J., Brun, V., de Pablo Llorente, V., Franczak, M., Frantsvåg, J. E., Hersperger, O., Klaus, T., Kramer, B., Kuchma, I., Laakso, M., Manista, F., Melinščak Zlodi, I., Mounier, P., Pölönen, J., Pontille, D., … Wnuk, M. (2023). Institutional Publishing in the ERA: Results from the DIAMAS survey. Zenodo. https://doi.org/10.5281/zenodo.10022184
Armengou, C., Edig, X. van ., Laakso, M., & Umerle, T. (2023). CRAFT-OA Deliverable 3.1 Report on Standards for Best Publishing Practices and Basic Technical Requirements in the Light of FAIR Principles (Draft). Zenodo. https://doi.org/10.5281/zenodo.8112662
Facts and figures—Portico. (2024). Portico. https://www.portico.org/coverage/facts-and-figures/FAQ - CLOCKSS. (2024). https://clockss.org/faq/
For Publishers—The Fatcat Guide. (n.d.). Retrieved 3 July 2024, from https://guide.fatcat.wiki/publishers.html
How CLOCKSS Works—CLOCKSS. (2024). CLOCKSS. https://clockss.org/about/how-clockss-works/
How the Internet Archive is Ensuring Permanent Access to Open Access Journal Articles | Internet Archive Blogs. (2020, September 15). Internet Archive Blogs. https://blog.archive.org/2020/09/15/how-the-internet-archive-is-ensuring-permanent-access-to-open-access-journal-articles/
Millman, D. (Director). (2020). Preservation of New Forms of Scholarship. https://www.cni.org/topics/digital-preservation/preservation-of-new-forms-of-scholarship
Regan, S. (2016). Strategies for Expanding E-Journal Preservation. The Serials Librarian, 70(1–4), Article 1–4. https://doi.org/10.1080/0361526X.2016.1144159
Sprout, B., & Jordan, M. (2018). Distributed digital preservation: Preserving open journal systems content in the PKP PN. Digital Library Perspectives, 34(4), Article 4. https://doi.org/10.1108/DLP-11-2017-0043
Wise, A. (2021). A Collaborative Approach to Preserving At-Risk Open Access Journals: “Journals Preserved Forever”. iPRES 2021 - 17th International Conference on Digital Preservation, Beijing. https://phaidra.univie.ac.at/detail/o:1424896
-